1. Why do we need a privacy language framework?
Personal and sensitive information is deeply embedded in language, and handling it is very costly due to different risks and regulations.
To address this issue, various solutions have been developed, but many are proprietary or inaccessible. These anonymization tools are often limited in both scope and accuracy.
Without a common standard or shared language, it is very challenging to compare these solutions and hold data administrators accountable for providing high standards of privacy protection.
To ensure data remains usable, shareable, and compliant with strict privacy regulations, we need a standardized, transparent, and accurate approach to data protection.
2. What is p5y?
p5y is a standardized framework for privacy methods to manage unstructured text containing personally identifiable and sensitive information. These methods include managing, substituting, redacting, and anonymizing personal data.
What makes p5y unique is that it addresses privacy concerns at the language level, reducing risks before they enter more complex and costly systems.
It draws inspiration from i18n (internationalization) and l10n (localization) frameworks. Just as they translate content into different locales, p5y "translates" sensitive data into privacy-safer formats, facilitating compliance with regulations like GDPR, HIPAA, and others.
This new framework streamlines the redaction and anonymization of personal data while preserving the usability and integrity of the original information. By adopting p5y, organizations can automate and standardize the handling of sensitive information, applying "privacy translation" similar to content translation for global markets, maximizing compliance, optimising business processes, and increasing user trust.

Fig 1: Privacy Masking as a p5y Translation Task
3. A 3-step approach to data privacy
This implementation is similar to the globalization method, which includes the following steps: Internationalization - preparing a product to support global markets by separating country- or language-specific content for adaptation; Localization - adapting the product for a specific market, and Quality Assurance.
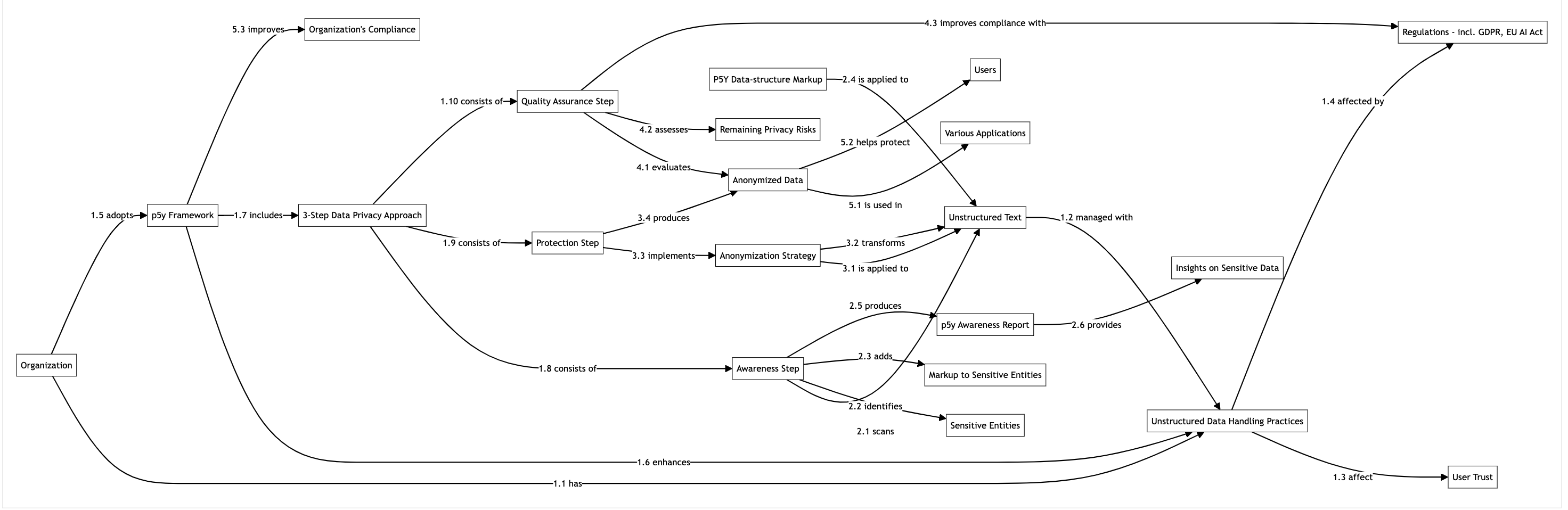
Fig 2: Flowchart of the 3 step implementation including orginisational motivation.
3.1 Awareness
The first step in p5y is to gain structured insights from unstructured text. This step scans the data for private and sensitive information and adds markup to these entities. It enables deriving quantitative and quality insights about the private data present and assesses risks and business needs.
At this step, we can produce a p5y Awareness Report about the data, including: types of personal data and distribution, personal data density, associated risk assessment, and regulatory readiness.
In the documentation, this Awareness step maps to the ontology layer and terminology in the Glossary.
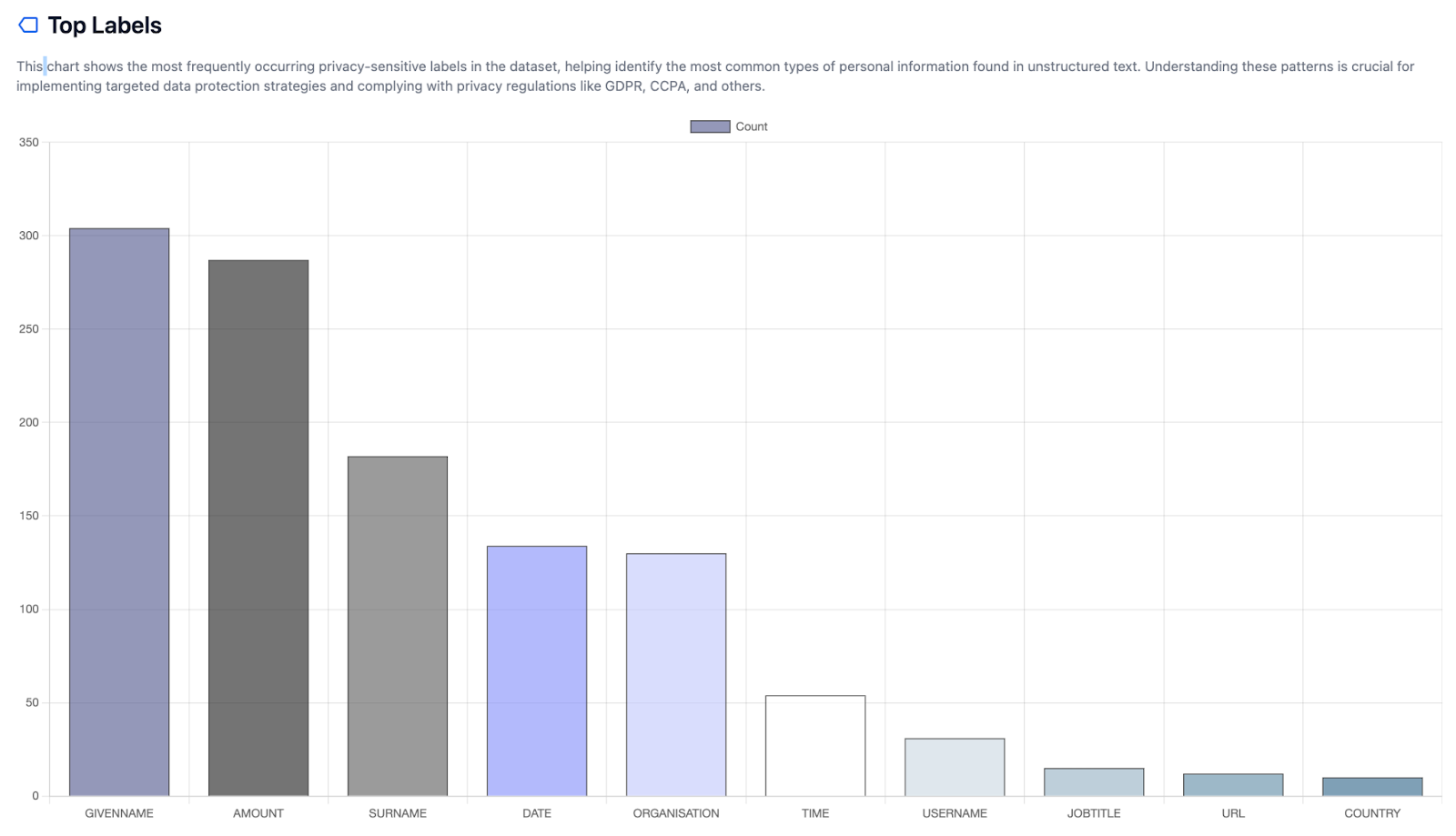
Fig 3: p5y Awareness Report (type of personal data and distribution).
3.2 Protection
The second step in p5y is to control the personal data identified in the texts. This includes deciding what to take out (e.g., directly identifying entities, bias-related attributes) and which anonymization strategy to use (e.g., masking, pseudonymization, k-anonymization).
The strategy depends on factors like how the data will be used, applicable regulations and risks, preferences, permissions, and context. By separating the personal data identification (Awareness) from the data anonymization (Protection), the framework prepares data for different use cases without needing separate anonymization pipelines.
In the documentation, this Protection step maps to the APMF.
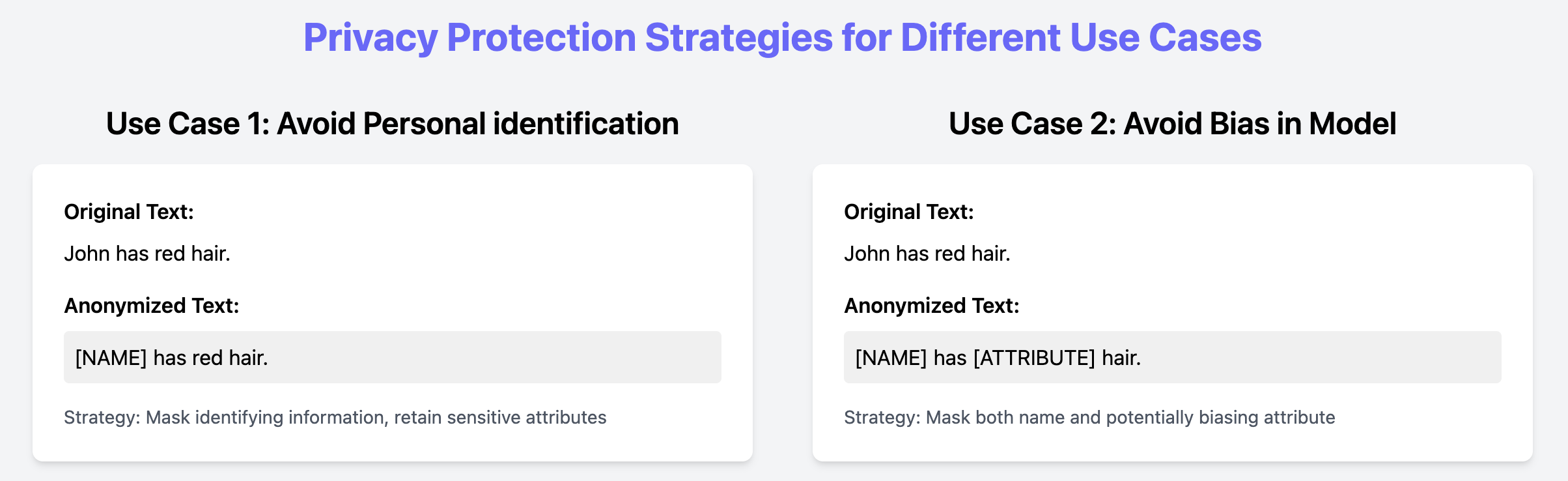
Fig 4: Showcase of different use-cases of anonymization tools.
3.3 Quality Assurance
The final step measures the remaining privacy risk after anonymization, evaluating how well the target entities have been anonymized and whether de-anonymization risks exist. This step involves expert human annotation and models to assess de-anonymization risks.
In the documentation, this QA step maps to the Error Taxonomy.

Fig 5: Showcase of the de-anonymization risk associated during the quality assurance step.
4. Permissible vs Non-Permissible Use Cases
The p5y framework is intended to facilitate data handling and processing, while maintaining high standards of privacy protection in line with regulatory standards. All uses that do not protect individuals' privacy and contravene privacy and AI regulations are not permitted. See the lists below for an overview of permissible and non-permissible uses.
Data Anonymization for Research and Analysis: Removing or masking PII from datasets to enable their use in scientific research or machine learning model training while preserving individual privacy.
Targeted Analysis of Personal Data: The framework should not be used to specifically analyze or profile individuals based on their personal information or to inform AI surveillance systems, as this would contradict its primary purpose of privacy protection.
Regulatory Compliance: Facilitating adherence to privacy regulations such as GDPR, HIPAA, and CCPA by systematically identifying and protecting sensitive information in various data formats.
Circumvention of Consent Requirements: p5y must not be utilized to process personal data without proper consent, under the guise of anonymization, when such consent is legally required.
Secure Data Sharing: Enabling the exchange of information between organizations or departments by redacting sensitive details while maintaining the utility of the underlying data.
De-anonymization Attempts: Any efforts to reverse the anonymization process or to cross-reference anonymized data with other sources to re-identify individuals are strictly prohibited.
Privacy-Preserving Publication: Preparing documents or datasets for public release by ensuring all personal identifiers are appropriately masked or removed.
Discriminatory Practices: The framework must not be used to facilitate any form of discrimination based on protected characteristics, even if such characteristics are inferred from anonymized data.
Data Minimization: Supporting the principle of data minimization by helping organizations acquire and retain only the necessary non-sensitive information for their operations.
Emotion Recognition and Social Scoring: In accordance with the EU AI Act, the p5y framework must not be used to facilitate or support emotion recognition systems in workplace and educational contexts, or to enable social scoring practices. These applications are explicitly banned due to their potential to infringe on individual privacy and fundamental rights.
6. Alignment with the EU AI Act
The permissible use cases of the p5y framework are designed to be compatible with the EU AI Act's emphasis on protecting fundamental rights and ensuring the ethical use of AI systems. Specifically:
- The framework supports the Act's requirements for transparency by providing clear mechanisms for data anonymization and pseudonymization.
- By facilitating privacy-preserving techniques, p5y aligns with the Act's focus on data minimization and purpose limitation in AI systems.
- The framework's emphasis on standardized privacy protection contributes to the Act's goal of creating trustworthy AI systems that respect user privacy.
- The framework aligns with the EU AI Act's emphasis on fair and non-discriminatory AI systems, by providing a methodology to remove sensitive attributes from data, which may induce unfair bias.
7. How does it look like from a practical perspective?
In p5y, we publish key data concepts including glossary terms, privacy mask data structure, placeholder tag mechanics, synthetic identities, labels, label sets, and machine learning tasks. See the glossary.
8. Contact Us
If you have any questions or want to know more about how the p5y framework can help your organization, feel free to reach out to us!