1. Warum brauchen wir ein Datenschutzsprachen-Framework?
Personenbezogene und sensible Informationen sind tief im Sprachmaterial eingebettet, und ihre Verarbeitung ist aufgrund unterschiedlicher Risiken und Vorschriften sehr kostspielig.
Um dieses Problem zu adressieren, wurden verschiedene Lösungen entwickelt, doch viele sind proprietär oder schwer zugänglich. Diese Anonymisierung-Tools sind häufig sowohl im Umfang als auch in der Genauigkeit begrenzt.
Ohne einen gemeinsamen Standard bzw. eine geteilte Sprache ist es sehr schwierig, diese Lösungen zu vergleichen und Datenverantwortliche für hohe Standards des Datenschutzes zur Rechenschaft zu ziehen.
Damit Daten nutzbar, teilbar und mit strengen Datenschutz-Vorschriften vereinbar bleiben, brauchen wir einen standardisierten, transparenten und präzisen Ansatz für den Schutz von Daten.
2. Was ist p5y?
p5y ist ein standardisiertes Framework für Datenschutz-Methoden, um unstrukturierte Texte mit personenbezogenen und sensiblen Informationen zu verwalten. Dazu gehören das Verwalten, Ersetzen, Redigieren und die Anonymisierung von personenbezogenen Daten.
Das Besondere an p5y ist, dass es Datenschutz auf Sprachebene adressiert und Risiken reduziert, bevor sie in komplexere und teurere Systeme gelangen.
p5y ist von i18n- (Internationalisierung) und l10n- (Lokalisierung) Frameworks inspiriert. So wie sie Inhalte in verschiedene Locales übersetzen, „übersetzt“ p5y sensible Daten in datenschutz-sicherere Formate und erleichtert so die Einhaltung von DSGVO, HIPAA und weiteren Regelwerken.
Dieses neue Framework vereinfacht die Redaktion und Anonymisierung von personenbezogenen Daten, während Nutzbarkeit und Integrität der Originalinformation erhalten bleiben. Durch die Einführung von p5y können Organisationen den Umgang mit sensiblen Informationen automatisieren und standardisieren und eine „Privacy-Übersetzung“ ähnlich der Content-Übersetzung für globale Märkte anwenden – für maximale Compliance, optimierte Geschäftsprozesse und mehr Vertrauen.

Abb. 1: Privacy Masking als p5y-Übersetzungsaufgabe
3. Ein 3‑Stufen-Ansatz für Datenschutz
Diese Implementierung ist vergleichbar mit der Globalisierungs-Methode, die die folgenden Schritte umfasst: Internationalisierung – ein Produkt für globale Märkte vorbereiten, indem länderspezifische bzw. sprachspezifische Inhalte getrennt werden; Lokalisierung – das Produkt für einen spezifischen Markt anpassen; und Qualitätssicherung.
Abb. 2: Flussdiagramm der 3‑Stufen-Implementierung inklusive organisatorischer Motivation.
3.1 Awareness
Der erste Schritt in p5y besteht darin, aus unstrukturiertem Text strukturierte Erkenntnisse zu gewinnen. Dabei werden Daten auf private und sensible Informationen gescannt und diese Entitäten markiert. So lassen sich quantitative und qualitative Einblicke in die vorhandenen privaten Daten ableiten und Risiken sowie Business-Anforderungen bewerten.
In diesem Schritt kann ein p5y-Awareness-Report erstellt werden, u. a. zu: Arten und Verteilung von personenbezogenen Daten, Dichte von personenbezogenen Daten, zugehörige Risikobewertung und regulatorische Bereitschaft.
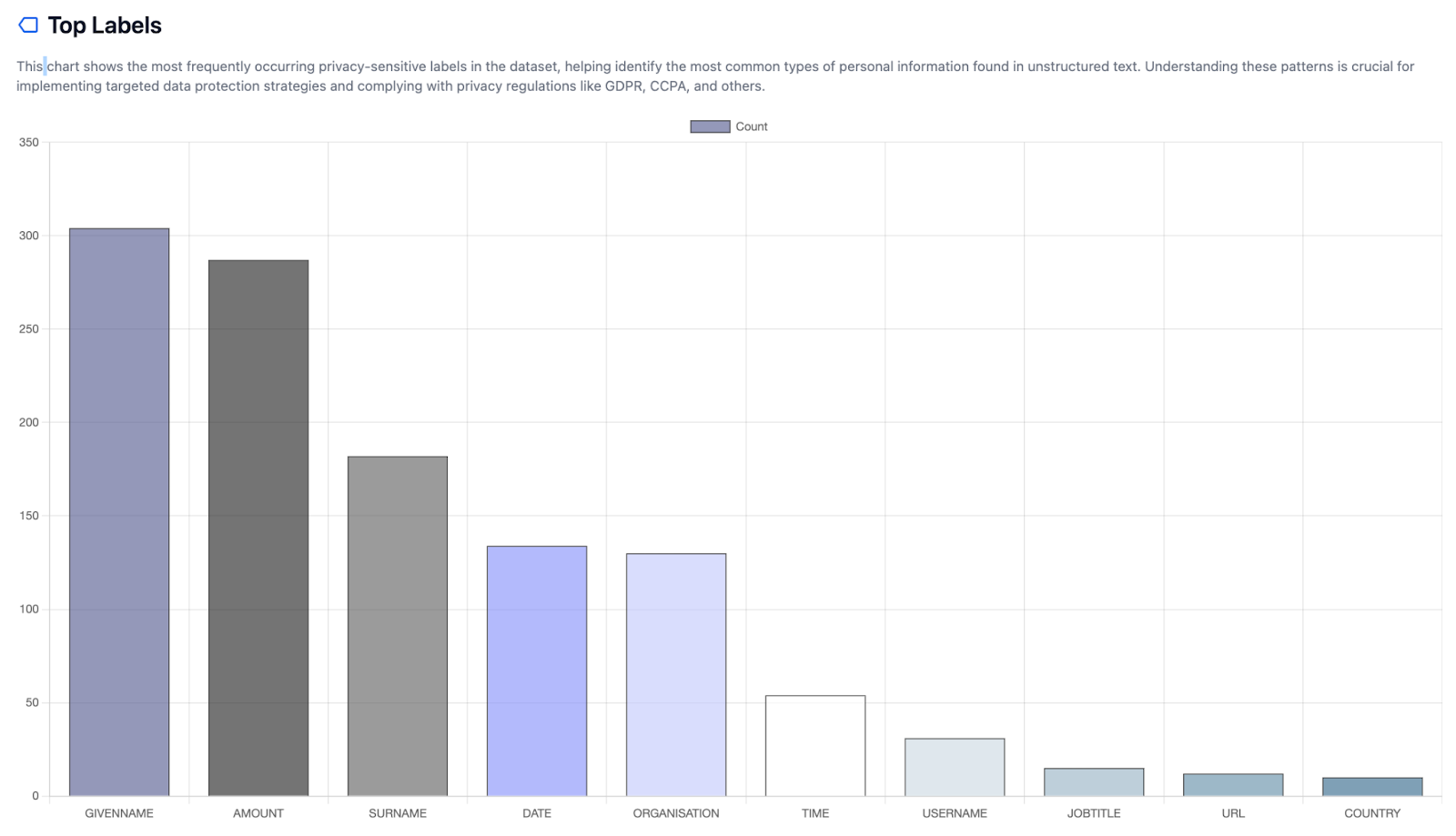
Abb. 3: p5y Awareness-Report (Art und Verteilung von personenbezogenen Daten).
3.2 Schutz
Der zweite Schritt in p5y besteht darin, die im Text identifizierten personenbezogenen Daten zu kontrollieren. Dazu gehört zu entscheiden, was entfernt wird (z. B. direkt identifizierende Entitäten, Bias-relevante Attribute) und welche Anonymisierungs-Strategie genutzt wird (z. B. Masking, Pseudonymisierung, k‑Anonymisierung).
Die Strategie hängt von Faktoren wie Verwendungszweck, anwendbaren Vorschriften und Risiken, Präferenzen, Berechtigungen und Kontext ab. Durch die Trennung von Identifikation (Awareness) und Anonymisierung (Schutz) bereitet das Framework Daten für verschiedene Use Cases vor, ohne separate Anonymisierung-Pipelines zu benötigen.
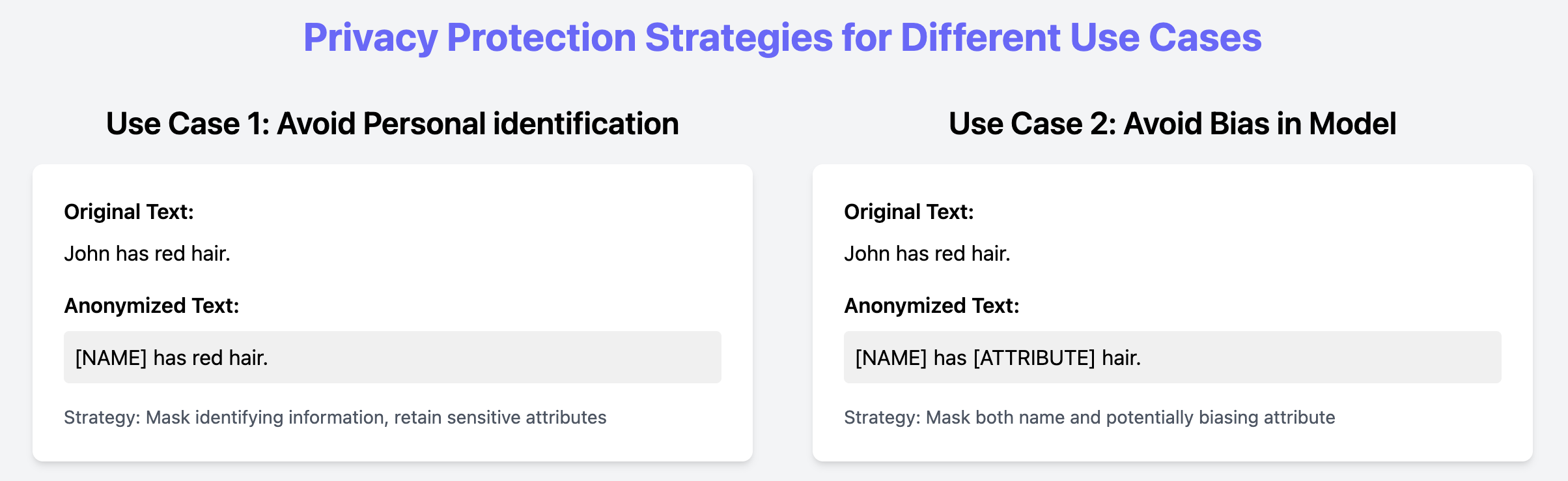
Abb. 4: Beispiele verschiedener Use Cases von Anonymisierung-Tools.
3.3 Qualitätssicherung
Der letzte Schritt misst das verbleibende Datenschutz-Risiko nach der Anonymisierung und bewertet, wie gut die Ziel-Entitäten anonymisiert wurden und ob Risiken der De‑Anonymisierung bestehen. Dieser Schritt beinhaltet Expertenannotation durch Menschen sowie Modelle zur Bewertung dieser Risiken.

Abb. 5: Beispiele für De‑Anonymisierung-Risiken im Schritt der Qualitätssicherung.
4. Erlaubte vs. nicht erlaubte Anwendungsfälle
Das p5y-Framework soll die Verarbeitung von Daten erleichtern und dabei hohe Standards des Datenschutzes im Einklang mit regulatorischen Vorgaben gewährleisten. Alle Nutzungen, die die Privatsphäre von Personen nicht schützen und gegen Datenschutz- und KI-Regelungen verstoßen, sind nicht erlaubt. Unten findet sich eine Übersicht.
Daten-Anonymisierung für Forschung und Analyse: Entfernen oder Maskieren von PII, um Datensätze in wissenschaftlicher Forschung oder beim Training von ML‑Modellen zu nutzen – bei gleichzeitiger Wahrung der Privatsphäre.
Zielgerichtete Analyse von personenbezogenen Daten: Das Framework darf nicht genutzt werden, um Personen gezielt zu analysieren oder zu profilieren oder KI‑Überwachung zu unterstützen, da dies dem Zweck des Datenschutzes widerspricht.
Regulatorische Compliance: Unterstützung bei der Einhaltung von Datenschutz-Vorschriften wie DSGVO, HIPAA und CCPA durch systematisches Identifizieren und Schützen sensibler Informationen in unterschiedlichen Datenformaten.
Umgehung von Einwilligungsanforderungen: p5y darf nicht dazu genutzt werden, personenbezogene Daten ohne gültige Einwilligung zu verarbeiten – unter dem Vorwand der Anonymisierung –, wenn Einwilligung rechtlich erforderlich ist.
Sicheres Data‑Sharing: Austausch von Informationen zwischen Organisationen oder Abteilungen durch Redigieren sensibler Details – bei Erhalt der Daten‑Nutzbarkeit.
De‑Anonymisierung-Versuche: Jegliche Bemühungen, den Anonymisierung-Prozess umzukehren oder anonymisierte Daten mit anderen Quellen zu verknüpfen, um Personen zu re‑identifizieren, sind strikt untersagt.
Datenschutzfreundliche Veröffentlichung: Vorbereitung von Dokumenten oder Datensätzen für die öffentliche Veröffentlichung, indem alle personenbezogenen Identifikatoren angemessen maskiert oder entfernt werden.
Diskriminierende Praktiken: Das Framework darf nicht eingesetzt werden, um Diskriminierung auf Basis geschützter Merkmale zu ermöglichen – selbst dann nicht, wenn solche Merkmale aus anonymisierten Daten abgeleitet werden.
Datenminimierung: Unterstützung des Prinzips der Datenminimierung, indem Organisationen nur die notwendigen, nicht sensiblen Informationen erwerben und behalten.
Emotionserkennung und Social Scoring: Gemäß EU AI Act darf das p5y-Framework nicht zur Unterstützung von Emotionserkennungssystemen in Arbeits- und Bildungskontexten oder zur Ermöglichung von Social Scoring genutzt werden. Diese Anwendungen sind ausdrücklich verboten, da sie die Privatsphäre und grundlegende Rechte beeinträchtigen können.
6. Ausrichtung am EU AI Act
Die erlaubten Anwendungsfälle des p5y-Frameworks sind so gestaltet, dass sie mit dem Fokus des EU AI Act auf den Schutz grundlegender Rechte und die ethische Nutzung von KI‑Systemen kompatibel sind. Konkret:
- Das Framework unterstützt die Transparenzanforderungen des Acts durch klare Mechanismen zur Anonymisierung und Pseudonymisierung.
- Durch datenschutz‑wahrende Techniken ist p5y im Einklang mit dem Fokus des Acts auf Datenminimierung und Zweckbindung in KI‑Systemen.
- Die Betonung standardisierten Datenschutzes trägt zum Ziel bei, vertrauenswürdige KI‑Systeme zu schaffen, die die Privatsphäre der Nutzer respektieren.
- Das Framework unterstützt faire und nicht diskriminierende KI‑Systeme, indem es eine Methodik bereitstellt, um sensible Attribute aus Daten zu entfernen, die sonst zu unfairen Bias‑Effekten führen können.
7. Wie sieht das aus praktischer Perspektive aus?
In p5y veröffentlichen wir zentrale Datenkonzepte, darunter Glossarbegriffe, die Privacy‑Mask‑Datenstruktur, Placeholder‑Tag‑Mechaniken, synthetische Identitäten, Labels, Label‑Sets und ML‑Tasks. Siehe Glossar.
8. Kontakt
Wenn Sie Fragen haben oder mehr darüber erfahren möchten, wie das p5y-Framework Ihrer Organisation helfen kann, melden Sie sich gern bei uns!