1. Perché abbiamo bisogno di un framework di linguaggio per la privacy?
Le informazioni personali e sensibili sono profondamente incorporate nel linguaggio, e gestirle è molto costoso a causa di rischi e regolamenti diversi.
Per affrontare questo problema, sono state sviluppate varie soluzioni, ma molte sono proprietarie o inaccessibili. Questi strumenti di anonimizzazione sono spesso limitati sia in termini di copertura sia di accuratezza.
Senza uno standard comune o un linguaggio condiviso, è molto difficile confrontare queste soluzioni e rendere responsabili gli amministratori dei dati nel fornire elevati standard di privacy.
Per garantire che i dati rimangano utilizzabili, condivisibili e conformi a rigorose normative sulla privacy, serve un approccio standardizzato, trasparente e accurato alla protezione dei dati.
2. Che cos’è p5y?
p5y è un framework standardizzato di metodi di privacy per gestire testi non strutturati che contengono informazioni personali identificabili e sensibili. Questi metodi includono gestione, sostituzione, redazione e anonimizzazione dei dati personali.
Ciò che rende p5y unico è che affronta i problemi di privacy a livello di linguaggio, riducendo i rischi prima che entrino in sistemi più complessi e costosi.
Si ispira ai framework i18n (internazionalizzazione) e l10n (localizzazione). Così come essi traducono contenuti in diverse lingue e mercati, p5y “traduce” i dati sensibili in formati più sicuri dal punto di vista della privacy, facilitando la conformità a GDPR, HIPAA e altre normative.
Questo nuovo framework semplifica la redazione e l’anonimizzazione dei dati personali preservando l’utilità e l’integrità delle informazioni originali. Adottando p5y, le organizzazioni possono automatizzare e standardizzare la gestione delle informazioni sensibili, applicando una “traduzione della privacy” analoga alla traduzione dei contenuti per i mercati globali, massimizzando la conformità, ottimizzando i processi e aumentando la fiducia degli utenti.

Fig 1: Privacy Masking come compito di traduzione p5y
3. Un approccio in 3 fasi alla privacy dei dati
Questa implementazione è simile al metodo di globalizzazione, che include i seguenti passaggi: Internazionalizzazione – preparare un prodotto per supportare i mercati globali separando i contenuti specifici di paese o lingua; Localizzazione – adattare il prodotto a un mercato specifico; e Quality Assurance.
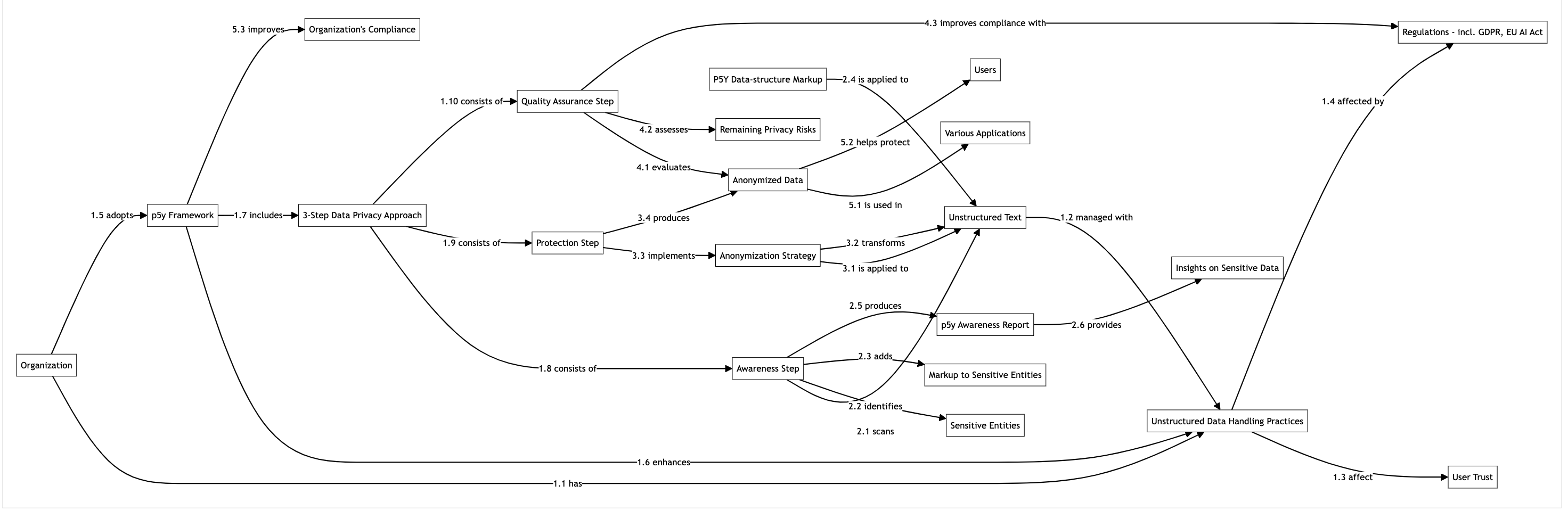
Fig 2: Diagramma di flusso dell’implementazione in 3 fasi, inclusa la motivazione organizzativa.
3.1 Awareness
Il primo passo in p5y è ottenere insight strutturati da testo non strutturato. Questa fase analizza i dati alla ricerca di informazioni private e sensibili e aggiunge markup a queste entità. Permette di derivare insight quantitativi e qualitativi sui dati privati presenti e di valutare rischi e necessità di business.
In questa fase possiamo produrre un report di Awareness p5y sul dataset, includendo: tipi di dati personali e distribuzione, densità di dati personali, valutazione del rischio e readiness regolatoria.
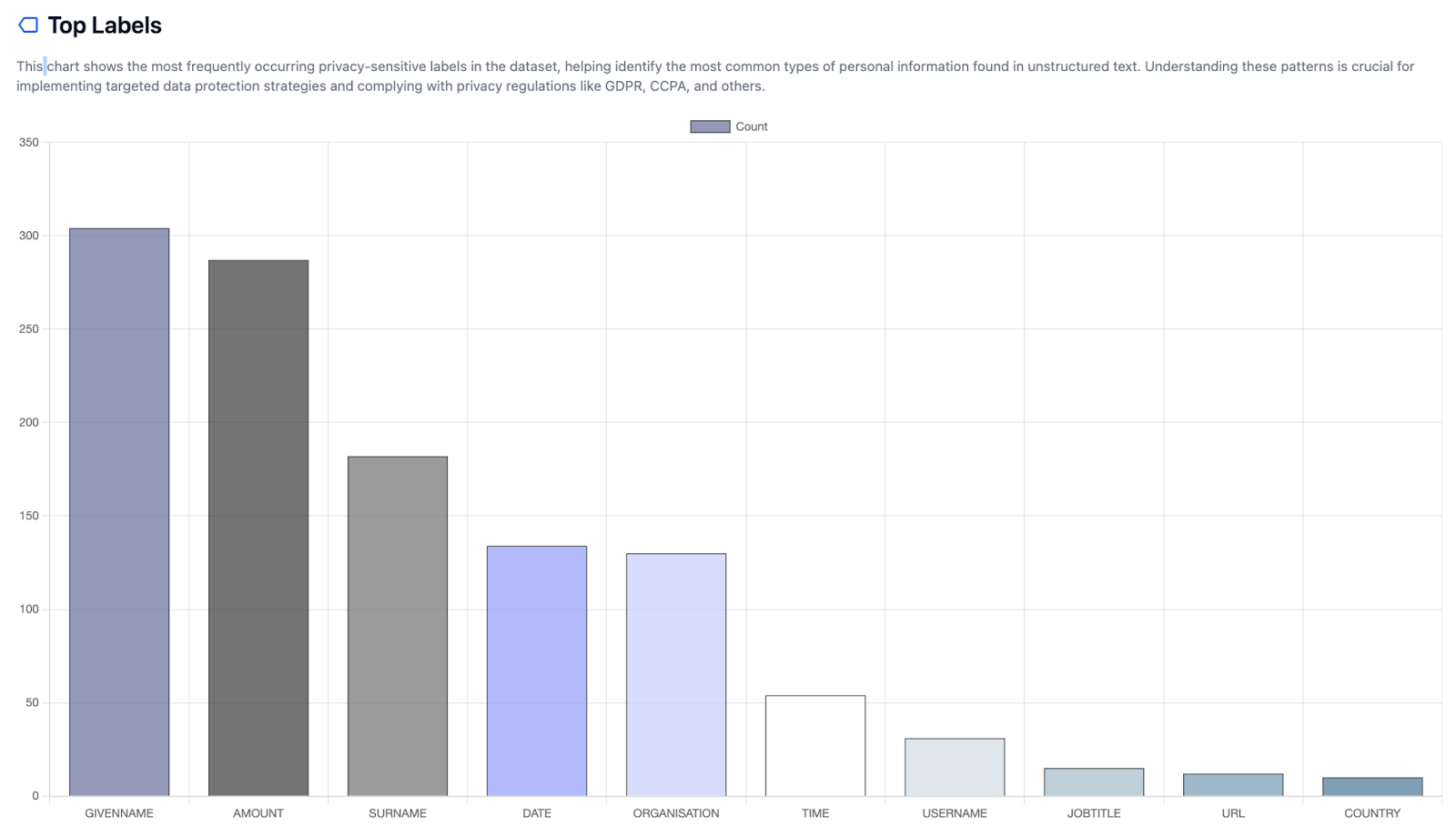
Fig 3: p5y Report di Awareness (tipo di dati personali e distribuzione).
3.2 Protezione
Il secondo passo in p5y è controllare i dati personali identificati nei testi. Questo include decidere cosa rimuovere (ad es. entità direttamente identificative, attributi legati ai bias) e quale strategia di anonimizzazione usare (ad es. masking, pseudonimizzazione, k-anonimizzazione).
La strategia dipende da fattori come l’uso previsto dei dati, le normative applicabili e i rischi, preferenze, permessi e contesto. Separando l’identificazione dei dati personali (Awareness) dalla anonimizzazione (Protezione), il framework prepara i dati per diversi casi d’uso senza necessitare pipeline distinte.
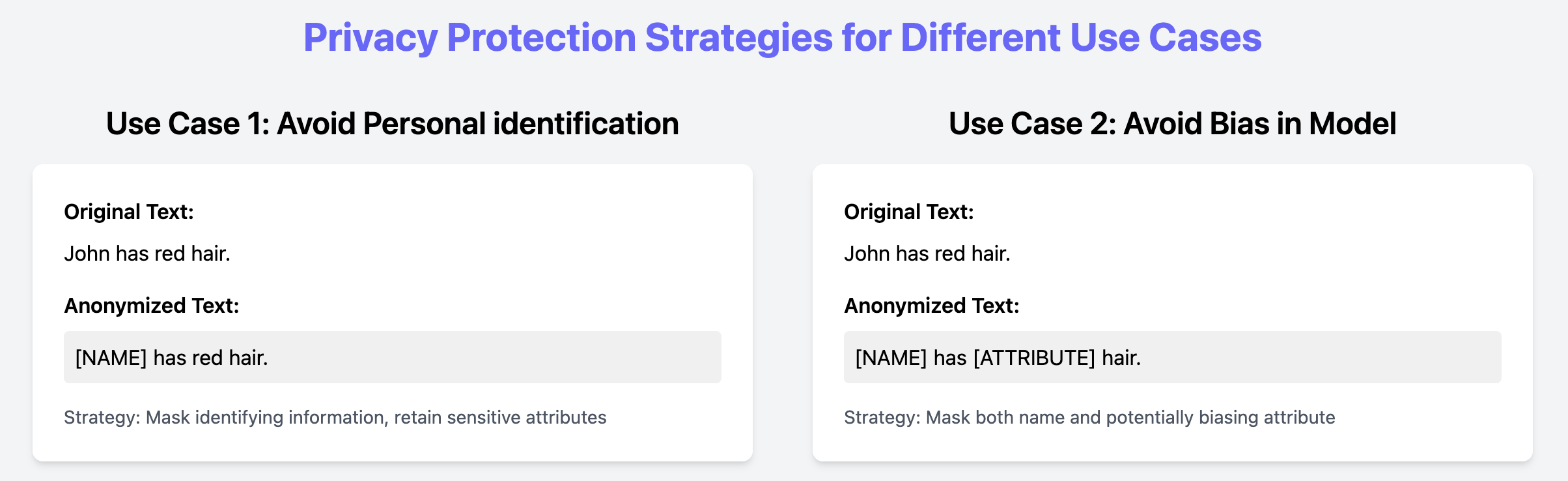
Fig 4: Panoramica di diversi casi d’uso di strumenti di anonimizzazione.
3.3 Quality Assurance
L’ultimo passo misura il rischio residuo di privacy dopo l’anonimizzazione, valutando quanto bene le entità target siano state anonimizzate e se esistono rischi di de-anonimizzazione. Questa fase include annotazione umana esperta e modelli per valutare tali rischi.

Fig 5: Panoramica del rischio di de-anonimizzazione associato durante la fase di quality assurance.
4. Casi d’uso consentiti vs non consentiti
Il framework p5y è pensato per facilitare la gestione e l’elaborazione dei dati mantenendo elevati standard di privacy in linea con gli standard normativi. Tutti gli utilizzi che non proteggono la privacy delle persone e che contravvengono alle normative su privacy e AI non sono consentiti. Vedi qui sotto una panoramica.
Anonimizzazione dei dati per ricerca e analisi: rimozione o mascheramento delle PII per abilitare ricerca scientifica o training di modelli ML preservando la privacy.
Analisi mirata dei dati personali: il framework non deve essere usato per profilare individui o per sistemi di sorveglianza, poiché ciò contraddice il suo scopo principale di protezione della privacy.
Conformità normativa: supporto all’aderenza a normative come GDPR, HIPAA e CCPA tramite identificazione e protezione sistematica delle informazioni sensibili.
Elusione dei requisiti di consenso: p5y non deve essere utilizzato per processare dati personali senza consenso, sotto la copertura dell’anonimizzazione, quando il consenso è legalmente richiesto.
Condivisione sicura dei dati: scambio di informazioni tra organizzazioni o dipartimenti redigendo dettagli sensibili pur mantenendo utilità dei dati.
Tentativi di de-anonimizzazione: qualsiasi tentativo di invertire il processo di anonimizzazione o di re-identificare persone incrociando dati con altre fonti è severamente vietato.
Pubblicazione privacy-preserving: preparare documenti o dataset per rilascio pubblico assicurando che tutti gli identificatori personali siano mascherati o rimossi.
Pratiche discriminatorie: il framework non deve essere usato per facilitare discriminazioni basate su caratteristiche protette, anche se inferite da dati anonimizzati.
Minimizzazione dei dati: supportare il principio di minimizzazione aiutando le organizzazioni ad acquisire e conservare solo le informazioni non sensibili necessarie.
Riconoscimento delle emozioni e social scoring: in linea con l’EU AI Act, il framework p5y non deve supportare sistemi di riconoscimento delle emozioni in contesti lavorativi o educativi, né abilitare pratiche di social scoring.
6. Allineamento con l’EU AI Act
I casi d’uso consentiti del framework p5y sono progettati per essere compatibili con l’enfasi dell’EU AI Act sulla protezione dei diritti fondamentali e sull’uso etico dei sistemi di AI. In particolare:
- Il framework supporta i requisiti di trasparenza dell’Act fornendo meccanismi chiari per anonimizzazione e pseudonimizzazione.
- Facilitando tecniche che preservano la privacy, p5y si allinea con l’attenzione dell’Act alla minimizzazione dei dati e alla limitazione delle finalità.
- L’enfasi sulla protezione standardizzata della privacy contribuisce all’obiettivo di creare sistemi di AI affidabili che rispettino la privacy degli utenti.
- Il framework si allinea con l’enfasi dell’EU AI Act su sistemi di AI equi e non discriminatori, fornendo una metodologia per rimuovere attributi sensibili dai dati che potrebbero indurre bias ingiusti.
7. Come appare da una prospettiva pratica?
In p5y, stiamo pubblicando concetti chiave, inclusi termini di glossario, struttura dati della privacy mask, meccanismi dei tag placeholder, identità sintetiche, label, label set e task di machine learning. Vedi il glossario.
8. Contattaci
Se hai domande o vuoi saperne di più su come il framework p5y può aiutare la tua organizzazione, non esitare a contattarci!