1. Vì sao chúng ta cần một khung ngôn ngữ quyền riêng tư?
Thông tin cá nhân và thông tin nhạy cảm được nhúng sâu trong ngôn ngữ, và việc xử lý chúng thường rất tốn kém do nhiều rủi ro và quy định khác nhau.
Để giải quyết vấn đề này, đã có nhiều giải pháp được phát triển, nhưng nhiều giải pháp là độc quyền hoặc khó tiếp cận. Các công cụ ẩn danh hóa thường bị giới hạn cả về phạm vi lẫn độ chính xác.
Nếu không có một tiêu chuẩn chung hoặc một ngôn ngữ dùng chung, việc so sánh các giải pháp này và buộc các bên quản trị dữ liệu chịu trách nhiệm về tiêu chuẩn quyền riêng tư là rất khó khăn.
Để đảm bảo dữ liệu vẫn hữu ích, có thể chia sẻ và tuân thủ các quy định quyền riêng tư nghiêm ngặt, chúng ta cần một cách tiếp cận tiêu chuẩn hóa, minh bạch và chính xác cho việc bảo vệ dữ liệu.
2. p5y là gì?
p5y là một khuôn khổ tiêu chuẩn hóa cho các phương pháp quyền riêng tư nhằm quản lý văn bản không có cấu trúc chứa thông tin nhận dạng cá nhân và nhạy cảm. Các phương pháp này bao gồm quản lý, thay thế, biên tập/che (redact) và ẩn danh hóa dữ liệu cá nhân.
Điểm khiến p5y khác biệt là nó xử lý các vấn đề quyền riêng tư ngay ở cấp độ ngôn ngữ, giảm rủi ro trước khi dữ liệu đi vào các hệ thống phức tạp và tốn kém hơn.
p5y lấy cảm hứng từ các khung i18n (quốc tế hóa) và l10n (bản địa hóa). Tương tự như việc dịch nội dung sang các ngôn ngữ/vùng khác nhau, p5y “dịch” dữ liệu nhạy cảm sang các định dạng an toàn hơn về quyền riêng tư, giúp tuân thủ các quy định như GDPR, HIPAA, và các quy định khác.
Khuôn khổ này giúp tinh gọn việc biên tập/che và ẩn danh hóa dữ liệu cá nhân trong khi vẫn giữ được tính hữu ích và toàn vẹn của thông tin gốc. Bằng cách áp dụng p5y, tổ chức có thể tự động hóa và chuẩn hóa việc xử lý thông tin nhạy cảm, áp dụng “dịch quyền riêng tư” tương tự như dịch nội dung cho thị trường toàn cầu, tối đa hóa tuân thủ, tối ưu quy trình và tăng niềm tin của người dùng.

Hình 1: Che quyền riêng tư như một nhiệm vụ dịch của p5y
3. Phương pháp 3 bước cho quyền riêng tư dữ liệu
Cách triển khai này tương tự phương pháp “globalization” (toàn cầu hóa sản phẩm), bao gồm các bước: Internationalization (quốc tế hóa) – chuẩn bị sản phẩm để hỗ trợ thị trường toàn cầu bằng cách tách nội dung theo quốc gia/ngôn ngữ để dễ thích nghi; Localization (bản địa hóa) – điều chỉnh sản phẩm cho một thị trường cụ thể; và Quality Assurance (đảm bảo chất lượng).
Hình 2: Lưu đồ 3 bước triển khai, bao gồm động lực ở cấp tổ chức.
3.1 Nhận diện
Bước đầu tiên trong p5y là thu được thông tin có cấu trúc từ văn bản không có cấu trúc. Bước này quét dữ liệu để tìm thông tin riêng tư và nhạy cảm, rồi gắn đánh dấu (markup) cho các thực thể đó. Nó cho phép suy ra các chỉ số định lượng và chất lượng về dữ liệu riêng tư hiện diện, đồng thời đánh giá rủi ro và nhu cầu kinh doanh.
Ở bước này, chúng ta có thể tạo một Báo cáo Nhận diện của p5y về dữ liệu, bao gồm: loại và phân bố dữ liệu cá nhân, mật độ dữ liệu cá nhân, đánh giá rủi ro liên quan và mức độ sẵn sàng về tuân thủ.
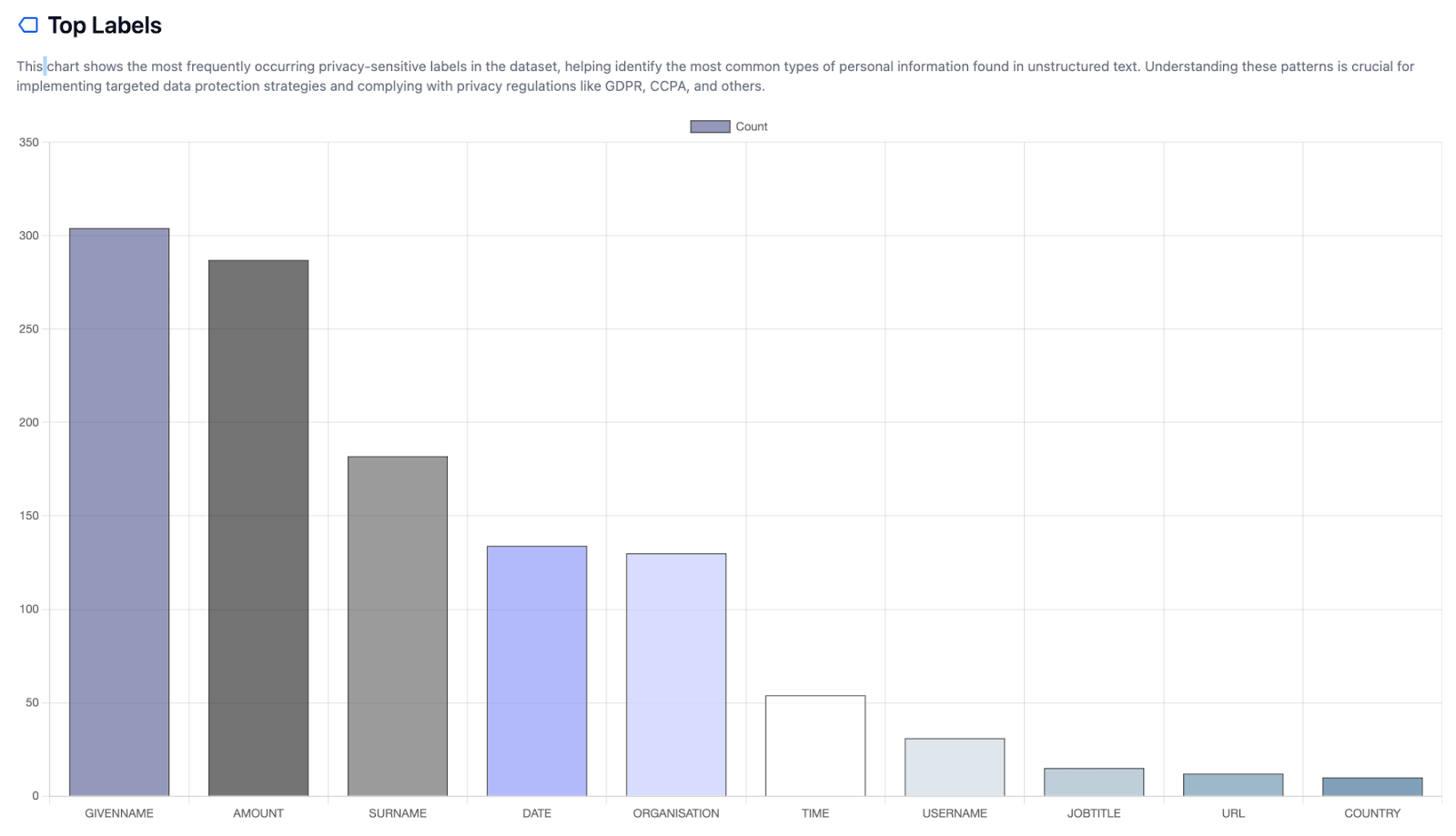
Hình 3: p5y Báo cáo Nhận diện (loại dữ liệu cá nhân và phân bố).
3.2 Bảo vệ
Bước thứ hai trong p5y là kiểm soát dữ liệu cá nhân đã được nhận diện trong văn bản. Việc này bao gồm quyết định những gì cần loại bỏ (ví dụ: thực thể nhận diện trực tiếp, thuộc tính liên quan đến thiên kiến) và chọn chiến lược ẩn danh hóa phù hợp (ví dụ: masking, pseudonymization, k-anonymization).
Chiến lược phụ thuộc vào cách dữ liệu sẽ được sử dụng, quy định áp dụng và rủi ro, sở thích, quyền hạn (permissions) và bối cảnh. Bằng cách tách nhận diện dữ liệu cá nhân (Nhận diện) khỏi ẩn danh hóa (Bảo vệ), khuôn khổ có thể chuẩn bị dữ liệu cho nhiều trường hợp sử dụng mà không cần các pipeline ẩn danh hóa riêng biệt.
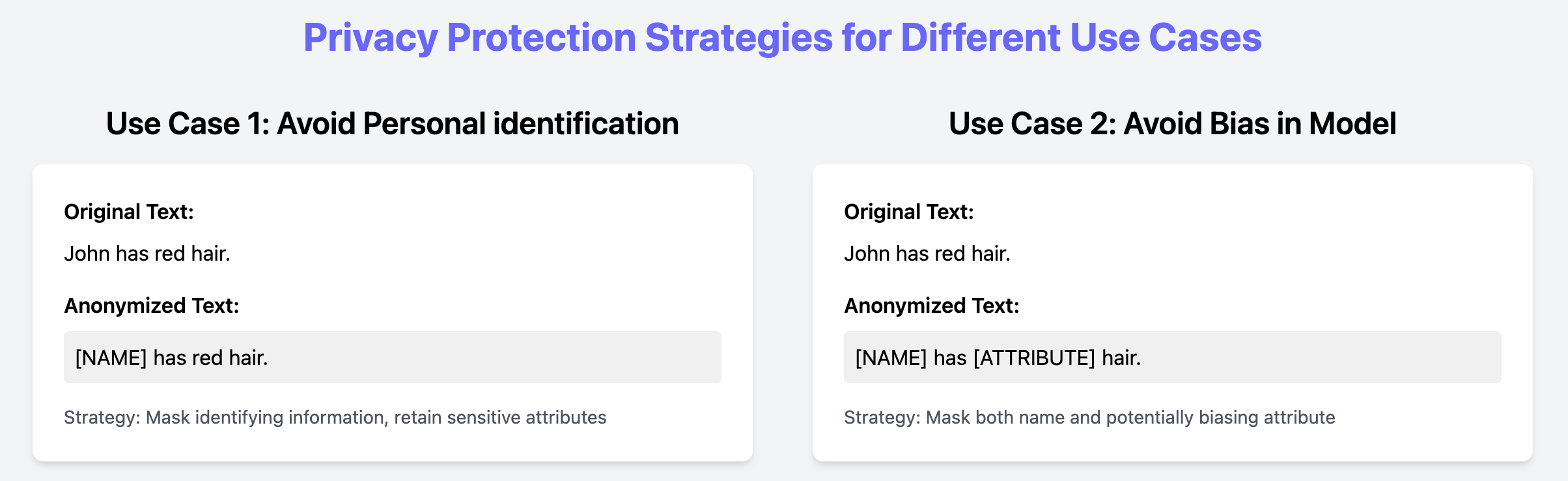
Hình 4: Minh họa các trường hợp sử dụng khác nhau của các công cụ ẩn danh hóa.
3.3 Đảm bảo chất lượng
Bước cuối cùng đo lường rủi ro quyền riêng tư còn lại sau ẩn danh hóa, đánh giá mức độ các thực thể mục tiêu đã được ẩn danh hóa và liệu có rủi ro giải ẩn danh hay không. Bước này thường bao gồm gán nhãn bởi chuyên gia và mô hình để đánh giá rủi ro giải ẩn danh.

Hình 5: Minh họa rủi ro giải ẩn danh trong bước đảm bảo chất lượng.
4. Trường hợp sử dụng được phép và không được phép
Khuôn khổ p5y được thiết kế để hỗ trợ xử lý dữ liệu trong khi vẫn duy trì tiêu chuẩn quyền riêng tư cao theo các chuẩn mực quy định. Mọi cách sử dụng không bảo vệ quyền riêng tư của cá nhân và vi phạm các quy định về quyền riêng tư và AI đều không được phép. Xem danh sách bên dưới để có cái nhìn tổng quan về các cách dùng được phép và không được phép.
Ẩn danh hóa dữ liệu cho nghiên cứu và phân tích: loại bỏ hoặc che PII khỏi tập dữ liệu để dùng trong nghiên cứu khoa học hoặc huấn luyện mô hình ML, đồng thời vẫn bảo vệ quyền riêng tư của cá nhân.
Phân tích nhắm mục tiêu dữ liệu cá nhân: khuôn khổ không nên được dùng để phân tích hoặc lập hồ sơ cá nhân dựa trên thông tin riêng của họ, hoặc để cung cấp dữ liệu cho hệ thống giám sát AI, vì điều này đi ngược mục tiêu cốt lõi là bảo vệ quyền riêng tư.
Tuân thủ quy định: hỗ trợ tuân thủ các quy định quyền riêng tư như GDPR, HIPAA và CCPA bằng cách nhận diện và bảo vệ thông tin nhạy cảm một cách có hệ thống trong nhiều định dạng dữ liệu khác nhau.
Lách yêu cầu về đồng ý (consent): p5y không được dùng để xử lý dữ liệu cá nhân khi thiếu đồng ý hợp lệ, dưới danh nghĩa ẩn danh hóa, trong khi pháp luật yêu cầu phải có đồng ý.
Chia sẻ dữ liệu an toàn: cho phép trao đổi thông tin giữa các tổ chức hoặc phòng ban bằng cách che/bôi đen các chi tiết nhạy cảm trong khi vẫn giữ được tính hữu ích của dữ liệu nền.
Nỗ lực giải ẩn danh: mọi cố gắng đảo ngược quá trình ẩn danh hóa hoặc đối chiếu dữ liệu đã ẩn danh với nguồn khác để tái định danh cá nhân đều bị nghiêm cấm.
Xuất bản bảo toàn quyền riêng tư: chuẩn bị tài liệu hoặc tập dữ liệu để công bố công khai bằng cách đảm bảo mọi định danh cá nhân đều được che hoặc loại bỏ phù hợp.
Thực hành phân biệt đối xử: khuôn khổ không được dùng để tạo điều kiện cho bất kỳ hình thức phân biệt đối xử nào dựa trên các đặc điểm được bảo vệ, kể cả khi các đặc điểm đó chỉ được suy luận từ dữ liệu đã ẩn danh.
Tối thiểu hóa dữ liệu: hỗ trợ nguyên tắc tối thiểu hóa dữ liệu bằng cách giúp tổ chức chỉ thu thập và lưu trữ những thông tin không nhạy cảm cần thiết cho hoạt động của họ.
Nhận diện cảm xúc và chấm điểm xã hội: theo Đạo luật AI của EU, khuôn khổ p5y không được dùng để hỗ trợ hệ thống nhận diện cảm xúc trong môi trường làm việc/giáo dục hoặc để triển khai chấm điểm xã hội. Các ứng dụng này bị cấm rõ ràng do có thể xâm phạm quyền riêng tư và các quyền cơ bản.
6. Phù hợp với Đạo luật AI của EU
Các trường hợp sử dụng được phép của khuôn khổ p5y được thiết kế để tương thích với trọng tâm của Đạo luật AI EU về bảo vệ quyền cơ bản và đảm bảo sử dụng AI một cách có đạo đức. Cụ thể:
- Khuôn khổ hỗ trợ yêu cầu về minh bạch của Đạo luật bằng cách cung cấp cơ chế rõ ràng cho ẩn danh hóa và pseudonymization.
- Bằng cách thúc đẩy các kỹ thuật bảo toàn quyền riêng tư, p5y phù hợp với trọng tâm của Đạo luật về tối thiểu hóa dữ liệu và giới hạn mục đích trong các hệ thống AI.
- Nhấn mạnh của khuôn khổ về bảo vệ quyền riêng tư theo chuẩn góp phần vào mục tiêu của Đạo luật trong việc xây dựng các hệ thống AI đáng tin cậy, tôn trọng quyền riêng tư của người dùng.
- Khuôn khổ phù hợp với trọng tâm của Đạo luật AI EU về các hệ thống AI công bằng và không phân biệt đối xử, bằng cách cung cấp phương pháp loại bỏ các thuộc tính nhạy cảm khỏi dữ liệu, vốn có thể gây thiên lệch không công bằng.
7. Trong thực tế trông như thế nào?
Trong p5y, chúng tôi công bố các khái niệm dữ liệu chính bao gồm các thuật ngữ trong bảng thuật ngữ, cấu trúc dữ liệu privacy mask, cơ chế thẻ placeholder, danh tính tổng hợp, nhãn, tập nhãn và các nhiệm vụ học máy. Xem bảng thuật ngữ.